%%{init: {'theme': 'base' } }%%
gitGraph
commit id: "1"
commit id: "2"
branch issue_1
checkout issue_1
commit id: "3" tag: "Pull-Request"
checkout issue_1
commit id: "4"
checkout main
merge issue_1
branch issue_2
commit id: "5"
7 Versionierung mit Git und GitHub
Definition 7.1 Versionierung ist ein Prozess, bei dem Änderungen an einem Dokument oder einer Datei nachverfolgt werden.
Die meisten Cloud-Dienste bieten inzwischen das Speichern von Dateiversionen an. Diese Funktionen sind in der Regel so gelöst, dass die Datei in regelmässigen Abständen gespeichert wird, so dass eine zeitliche Abfolge von geänderten Versionen entsteht. Für manche Dateiformate ist es möglich, einzelne Änderungen des Inhalts nachzuvollziehen.
Hinweis
Für die Arbeit mit Daten ist das Versionsmanagement wichtig, damit das Datenmanagement durchgängig und nachvollziehbar ist.
Das regelmässige Speichern von Dateien ist der Startpunkt für die eigentliche Versionierung, dem Versionsmanagement oder der Versionskontrolle (engl. Version Control).
Bei der Versionierung werden die Änderungen an einer Datei festgehalten und mit einer Versionsnummer gespeichert. Der entscheidende Unterschied zum regelmässigen Speichern auf Cloud-Diensten ist, dass einzelne Versionen für den späteren Gebrauch oder zur späteren Kontrolle markiert und wiederhergestellt werden können. Die Versionskontrolle stellt sicher, dass für jede Datei die jeweils aktuelle Version eindeutig definiert ist.
Die Versionierung betrifft alle erzeugenden Projektdateien. Dazu gehören:
- Datendateien
- Code-Dateien
- Code-Konfiguration
- Projektkonfiguration
- Dokumentation
Es gibt verschiedene Systeme für die Versionierung. Im Bereich der Software-Entwicklung und den Datenwissenschaften hat sich git als Industriestandard etabliert.
git ist ein verteiltes Versionierungssystem. Verteilt bedeutet dabei, dass die Versionierung mit allen teilnehmenden Systemen vollständig geteilt wird und es keine zentrale Instanz für die Versionierung gibt. Es handelt sich daher um ein redundantes Peer-to-Peer-System. git unterteilt die Versionierung in Projekte, den sog. Repositories, dass auf verschiedenen Computern repliziert bzw. ge-cloned wird. Dadurch erhält jeder Computer mit einem Repository-Clone eine vollständige Kopie der Versionierung eines Projekts.
Diese Kurzeinführung stellt die zentralen git-Konzepte für die tägliche Arbeit vor:
gitinstallieren- Repositories, Clone und Forks
- Dateiversionen einem Repository hinzufügen (commit)
- Pull und Push
- Branches, Merges und Pull-Requests
7.1 git installieren
git besteht im wesentlichen aus einem Kommandozeilen-Werkzeug, das alle Funktionen von git bereitstellt. Dieses Werkzeug wird oft auch als CLI-Tool bezeichnet. Es ist für die meisten GUI-Apps die Voraussetzung für die Arbeit. Ausserdem stellen nicht alle GUI-Apps alle git-Funktionen bereit und gelegentlich kann es in Spezialfällen notwendig sein, git direkt zu verwenden. Deshalb sollte git immer auf einem Computer installiert sein.
7.1.1 git unter MacOS installieren
Es wird dringend empfohlen die offiziell von Apple vertriebene Version von git zu verwenden.
Unter MacOS ist git Teil der internen Entwicklungsumgebung. Dazu sollte XCode installiert sein. XCode muss mindestens einmal gestartet worden sein, damit die Lizenzbedingungen erstmalig akzeptiert werden. Anschliessend müssen die XCode Command Line Tools dem System hinzugefügt werden. Wählen Sie die Version dieser Tools immer so aus, dass sie zu der von Ihnen installierten Version von XCode passt. Für diesen Download benötigen Sie einen Entwicker-Account auf Apple’s Entwicklerplattform. Dieser Account ist kostenlos. Nach der Installation der XCode Command Line Tools ist auch git auf Ihrem Rechner installiert.
7.1.2 git unter Windows installieren
Unter Windows stellt das Projekt git for Windows eine für Windows Systeme angepasste Version von git bereit. Diese Version bietet neben git zusätzliche Werkzeuge, mit denen sich Anleitungen leichter nachvollziehen lassen.
7.1.3 Grafische Oberflächen für git
GUI-Apps die Arbeit mit git. Für die Arbeit mit diesem Buch werden die folgenden Werkzeuge empfohlen.
- Visual Studio Code unterstützt
gitin der Basisinstallation. - GitLens ist eine Erweiterung für Visual Studio Code und bindet zusätzliche Funktionen für das Versionsmangement direkt in die IDE ein.
- GitHub Desktop stellt eine einfache Benutzeroberfläche für die Basisaufgaben mit GitHub am Computer Desktop bereit.
- GitKraken bietet unfangreiche Funktionen zum Versionsmanagement mit
git. Mit GitKraken lassen sich fast allegit-Aufgaben über die GUI lösen. Ausserdem ist GitKraken nicht auf GitHub als Hosting-Plattform beschränkt.
7.1.4 git-Hosting-Plattformen
git ist zuerst auf den eigenen Computer beschränkt. Für das Zusammenarbeiten mit anderen und die Sicherung der eigenen Versionierung empfiehlt sich die Verwendung einer sog. git-Hosting-Plattform. Eine git-Hosting-Plattform erlaubt es, die Versionierung eines Projekts online zu sichern und mit anderen zu teilen, die bietet Projektmanagementfunktionen sowie Automatisierungsmöglichkeiten, die über die Kernfunktionen von git hinausgehen.
Die wichtigsten git-Hosting-Plattformen mit gleichwertigem Funktionsumfang sind:
Jede dieser Plattformen benötigt ein eigenes Benutzerkonto.
Hinweis
Dieses Buch verwendet GitHub für Code-Beispiele, Diskussionen und andere Funktionen. GitLab und Gittea sind Alternativen zu GitHub mit gleichwertigen Funktionsumfang und ähneln sich bei der Bedienung und im Funktionsumfang stark. Aus Sicht der Projektorganisation sind die Plattformen fast identisch. Es gibt vor Allem emotionale und wirtschaftliche Gründe, sich für die eine oder die andere Plattform zu entscheiden.
7.2 git-Konzepte
7.2.1 Repositories, Clones und Forks
Die Grundlage der Versionierung mit git ist das Repository. Ein Repository enthält die Dateiversionen eines Projekts. Aus den Versionen kann das Projekt auf den Zustand zu jedem Versionierungszeitpunkt wiederhergestellt werden.
Ein Repository enthält alle versionierten Dateien und deren Versionen. Auf dem eigenen Computer sieht ein git-Repository ersteinmal wie ein normales Verzeichnis aus. Die Versionen sind in einer versteckten Versionsdatenbank gespeichert, über die mit dem git-Kommando oder einem entsprechenden GUI-Tool interagiert wird.
Um aus einem normalen Verzeichnis ein git-Repository zu erstellen, muss das Verzeichnis für git initianlisiert werden. Im Terminal kann ein beliebiges Verzeichnis zu einem Repository initialisiert werden.
git initgit-Repositories können aus zwei Arten synchronisiert werden: Durch Clone und durch Forks. Jede Kopie eines git-Repositories enthält immer alle Versionen des Projekts. Wird ein Repository auf einen anderen Computer synchronisiert, dann wird das entfernte Repository als Remote bezeichnet. Handelt es sich bei diesem Repository um ein Quell-Repository, dann wird dieses auch als Upstream-Repository bezeichnet. Die lokale Variante des Repositories wird auch als Downstream-Repository bezeichnet.
Zwei gleichwertige Kopien eines Repositories werden als Clone bezeichnet. Gleichwertig bedeutet, dass die Versionen zwischen diesen Repositories direkt synchronisierbar sind.
Neben gleichwertigen Repositories gibt es noch hierarchische Beziehungen zwischen Repositories. Dabei kann nur vom Upstream Remote direkt in die lokale Kopie sysnchronisiert werden. Änderungen im Downstream-Repository können nicht direkt in das Upstream Remote synchronisiert werden. Das Downstream Repository wird als Fork bezeichnet. Änderungen eines Forks können über sog. Pull-Requests an das Upstream-Repository gesendet werden.
7.2.2 Versionierungsstatus feststellen
Mit dem Kommando git status kann der aktuelle Änderungsstatus eines Repositories festgestellt werden. In einem frisch initialisierten Repository liefert dieses Kommando die folgende Meldung.
On branch main
No commits yet
nothing to commit (create/copy files and use "git add" to track)Wird einem leeren Repository eine neue Datei hinzugefügt, zeigt git status an, dass die neue Datei noch nicht versioniert wird. Als Beispiel wird die Datei README.md mit dem folgenden Inhalt erstellt.
# Mein erstes ProjektNach dem diese Datei gespeichert wurde, liefert git status die folgende Meldung.
On branch main
No commits yet
Untracked files:
(use "git add <file>..." to include in what will be committed)
README.md
nothing added to commit but untracked files present (use "git add" to track)7.2.3 Versionierung durch Commits
git muss mitgeteilt werden, dass eine neue, noch nicht verfolgte Datei in die Versionierung aufgenommen wird. Die Meldung von git status gibt den Hinweis, dass das Kommando dazu verwendet werden muss.
Im obigen Beispiel kann die neue mit git add README.md in die Versionierung aufgenommen werden.
Im Gegensatz zu Cloud-Speichern führt git keine automatische Synchronisation bei Änderungen einer Datei durch. Stattdessen müssen zu versionierende Dateien und Änderungen ihnen explizit versioniert werden. Auf den ersten Blick sieht das kompliziert aus, bietet im Entwicklungsprozess mehr Flexibilität und Kontrolle.
Die Versionierung erfolgt immer in zwei Schritten:
- Auswahl der zuversionierenden Dateien mit
git add. - Erstellen einer neuen Version mit den Änderungen in den ausgewählten Dateien mit
git commit.
Auf der Kommandozeile werden die beiden Schritte durch zwei Aufrufe von git:
# Alle geänderten und neuen Dateien für die Versionierung auswählen
git add .
# Eine neune Version für die ausgewählten Dateien erzeugen.
git commitFalls nur verfolgte Dateien in einer Version aufgenommen werden sollen, dann können die beiden Schritte mit dem folgenden Kommando zusammengefasst werden.
git commit -aSollen neue, noch nicht versionierte Dateien in die Versionierung aufgenommen werden, dann müssen diese Dateien zwingend mit git add ausgewählt werden.
GUI-Apps fassen die beiden Schritte automatisch zusammen.
Im obigen Beispiel wurde die Datei README.md bereits zur Versionierung markiert. Diese Datei soll nun versioniert werden. Das wird mit git commit erreicht. Wird git commit direkt aufgerufen, startet git den sog. Message-Editor, um die Meldung für diese Version einzugeben. git versucht einen Vorschlag für die Meldung vorzuschlagen. Diese Meldung kann übernommen werden, indem die Rautesymbole am Zeilenanfang gelöscht werden. Abschliessend muss die Meldung gespeichert und geschlossen werden, damit git die Meldung übernimmt.
git erfordert, dass alle Versionen eine Meldung haben, die kurz die vorgenommenen Änderungen beschreibt. Diese Versionsmeldung erlaubt es, die Entwicklung eines Projekts schrittweise nachzuvollziehen.
Hinweis: Es ist zwar prinzipiell möglich auch leere Versionsmeldungen zu speichern, dadurch lässt sich die Versionsgeschichte nur schwer reproduzieren. Ausserdem wird die Auswahl einer bestimmten Version erschwert, weil aus der Versionsnummer nicht direkt hervorgeht, welche Änderungen vorgenommen wurden.
Das Kommando git status zeigt nun an, dass keine Änderungen gefunden wurden.
Nachdem eine Version erstellt wurde, kann die Versionsgeschichte mit git log angezeigt werden. Das Ergebnis sieht nach dem initialen Commit des obigen Beispiels sieht etwas folgendermassen aus:
commit b281e4a03a4e71bcc41fa2f68e822b98c1555e1d (HEAD -> main)
Author: Christian Glahn <christian.glahn@zhaw.ch>
Date: Fri Aug 18 14:37:49 2023 +0200
Initial commit
new file: README.mdDie kryptische Symbolfolge in der ersten Zeile hinter dem Wort commit ist die Versionsnummer. Die Versionsnummer ist eindeutig im Projekt und über die meisten Projekte hinweg. In Klammern stehen die beiden Worte HEAD und main. HEAD zeigt die Markierung der aktuellen Version. main zeigt das Ende des aktuellen Versionszweig mit dem Namen main an. Dieser Information folgt der Name der Person, welche die Version erzeugt hat und dem Datum und der Uhrzeit, was den Versionszeitpunkt markiert. Abschliessend folgt die Versionsmeldung.
Dieser Schritt kann nun mit einer Änderung an der Datei README.md wiederholt werden. Hierzu wird zusätzlicher Text "Eine Übung zur Git Versionierung" ans Ende der Datei hizugefügt. Der Inhalt der Datei sollte nun wie folgt aussehen:
# Mein erstes Projekt
Eine Übung zur Versionierung mit git.Diese Änderungen werden nun mit git commit -a versioniert.
git log zeigt nun die folgende Information.
commit 1504d416bb1ef926fde4d5e949f3ed330d97b065 (HEAD -> main)
Author: Christian Glahn <christian.glahn@zhaw.ch>
Date: Fri Aug 18 15:27:19 2023 +0200
Zusatzinformation zum Projekt
modified: README.md
commit b281e4a03a4e71bcc41fa2f68e822b98c1555e1d
Author: Christian Glahn <christian.glahn@zhaw.ch>
Date: Fri Aug 18 15:26:36 2023 +0200
Initial commit
new file: README.mdDie beiden Markierungen HEAD und main wurden zur aktuellen Version verschoben.
7.2.4 Checkout
Eine Versionierung macht nur dann Sinn, wenn auf eine ältere Version zugegriffen werden kann. Das erlaubt das Kommando git checkout. Dieses Kommando benötigt eine Versionsnummer oder eine Markierung, um die entsprechede Version zuzugreifen.
So kann auf die erste Version im Projekt zugegriffen werden:
git checkout b281e4a03a4e71bcc41fa2f68e822b98c1555e1dDieses Kommando ersetzt alle Dateien im Arbeitsverzeichnis in den Zustand der angegebenen Version.
Der Inhalt der Datei README.md ist nun wieder wie folgt.
# Mein erstes ProjektDer Befehlt git log zeigt nun die Versionsgeschichte bis zum aktuell vorliegenden Inhalt.
commit b281e4a03a4e71bcc41fa2f68e822b98c1555e1d (HEAD)
Author: Christian Glahn <christian.glahn@zhaw.ch>
Date: Fri Aug 18 15:26:36 2023 +0200
Initial commit
new file: README.mdHier gilt es zu beachten, dass die Markiergung main nicht mehr angezeigt wird. Diese Markierung ist nicht verloren, liegt aber aus Sicht der aktuellen Version in der Zukunft und wird deshalb nicht dargestellt. Wenn diese Versionsnummer nicht notiert wurde, kann auf die “zukunftigen” Versionen nicht leicht zugegriffen werden. Damit wieder auf die letzte Version zugegriffen werden kann, kann die Markierung main verwendet werden.
git checkout mainMit diesem Kommando werden alle Dateien auf den neusten Stand gebracht. git log zeigt nun wieder die vollständige Versionsgeschichte.
7.2.6 Branching und Merging
Die Markierung main ist kein Tag, sondern markiert einen Versionszweig. Diese Markierung wandert mit jedem Commit immer zur neusten Version. Es ist möglich mehrere Versionszweige im gleichen Repository zu führen. Ein Versionszweig wird als Branch bezeichnet.
Die Versionszweige eines Repositories lassen sich mit dem Kommando git branch anzeigen. Im Beispiel-Repository liefert dieses Kommando das folgende Ergebnis.
* mainJedes git-Repository hat mindestens einen Versionszweig. Neuere Versionen von git verwenden main als Namen für diesen Haupt-Branch.
Versionszweige werden in der Praxis dafür verwendet, um komplexe Änderungen im Projekt vorzunehmen oder um zusammenzuarbeiten.
Um einen neuen Branch zu erstellen wird das Kommando git branch -c verwendet. Es fügt an der aktuell aktiven Version einen neuen Branch ein.
git checkout erste_version
git branch -c extrasDieses Kommando erstellt am Tag erste_version einen neuen Branch mit dem Namen extras. git branch zeigt nun das folgende Ergebnis.
* (HEAD detached at erste_version)
main
extrasUm den extras-Branch zu aktivieren, muss dieser nur git checkout extras aufgerufen werden.
git log zeigt nun als Versionsgeschichte.
commit b281e4a03a4e71bcc41fa2f68e822b98c1555e1d (HEAD -> extras, tag: erste_version)
Author: Christian Glahn <christian.glahn@zhaw.ch>
Date: Fri Aug 18 15:26:36 2023 +0200
Initial commit
new file: README.mdDer Pfeil von HEAD nach extras zeigt an, dass neue Versionen zum extras-Branch und nicht mehr zum main-Branch hinzugefügt werden. So lassen sich Verzweigungen umsetzen. Das veranschaulicht das folgende Beispiel: Es wird eine neue Datei mit dem Namen AUTHORS.md und dem folgenden Inhalt.
Christian Glahn (ZHAW)erstellt. Es handelt sich um eine neue Datei und deshalb muss sie mit git add zum Repository hinzugefügt und eine Version mit git commit erstellt werden.
git add AUTHORS.md
git commit -m "Autorenliste"git log zeigt nun als Versionsgeschichte:
commit 5d10e17be5a2fc0d987db10644b35c73224f51f2 (HEAD -> extras)
Author: Christian Glahn <christian.glahn@zhaw.ch>
Date: Fri Aug 18 16:58:01 2023 +0200
Autorenliste
commit b281e4a03a4e71bcc41fa2f68e822b98c1555e1d (tag: erste_version)
Author: Christian Glahn <christian.glahn@zhaw.ch>
Date: Fri Aug 18 15:26:36 2023 +0200
Initial commit
new file: README.mdDiese neue Datei existiert vorerst nur im extras-Branch. Diesem Branch können nun weitere Änderungen hinzugefügt werden.
Sind die Änderungen abgeschlossen, dann können diese Änderungen in den Hauptzweig übernommen werden. Dieses Zusammenführen von zwei Branches wird als Merge bezeichnet. Die folgenden Kommandos führen den Merge der Änderungen von extras in den main-Branch aus.
git checkout main
git merge -m "Extras übernehmen" extrasDieses Zusammenführen bindet die Versionen aus dem extras-Branch in den main-Branch ein. Es gehen also keine Versionen verloren. git log zeigt das.
commit 4f33342df57ec5f60b2ec1daeb581b49836f05bf (HEAD -> main)
Merge: 1504d41 5d10e17
Author: Christian Glahn <christian.glahn@zhaw.ch>
Date: Fri Aug 18 17:01:27 2023 +0200
Extras übernehmen
commit 5d10e17be5a2fc0d987db10644b35c73224f51f2 (extras)
Author: Christian Glahn <christian.glahn@zhaw.ch>
Date: Fri Aug 18 16:58:01 2023 +0200
Autorenliste
commit 1504d416bb1ef926fde4d5e949f3ed330d97b065
Author: Christian Glahn <christian.glahn@zhaw.ch>
Date: Fri Aug 18 15:27:19 2023 +0200
Zusatzinformation zum Projekt
modified: README.md
commit b281e4a03a4e71bcc41fa2f68e822b98c1555e1d (tag: erste_version)
Author: Christian Glahn <christian.glahn@zhaw.ch>
Date: Fri Aug 18 15:26:36 2023 +0200
Initial commit
new file: README.mdNun existiert die Datei AUTHORS.md auch im main-Branch.
7.2.7 Merge-Konflikte lösen
Gelegentlich entstehen beim Mergen Konflikte. Ein Merge-Konflikt sind widersprüchliche Inhalte an der gleichen Code-Position. Solche Konflikte können auch entstehen, wenn mehrere Personen gleichgzeitig auf dem gleichen Branch arbeiten.
git löst solche Widersprüche nicht selbst, sondern erfordert ein aktives Eingreifen der Entwickler:innen. Um diesen Schritt zu erleichtern, fügt git Markierungen für die Konflikte ein. Diese Markierungen sind in den aktiven Daten zu finden, aber sind keine eigenständigen Versionen im Repository.
Ein solcher Konflikt kann dadurch provoziert werden, indem im extras-Branch der Datei README.md am Ende zusätzlicher Text hinzugefügt wird, so dass die Datei den folgenden Inhalt hat.
# Mein erstes Projekt
Alle Information zu den Autoren finden sich in der Datei [AUTHORS.md]Wird nun versucht den extras und den main-Branch zusammenzuführen, meldet git merge den folgenden Konflikt:
Auto-merging README.md
CONFLICT (content): Merge conflict in README.md
Automatic merge failed; fix conflicts and then commit the result.Der Inhalt der Datei README.md zeigt nun den Merge-Konflikt.
# Mein erstes Projekt
<<<<<<< HEAD
Eine Übung zur Versionierung mit git.
=======
Alle Information zu den Autoren finden sich in der Datei [AUTHORS.md].
>>>>>>> extrasDurch die Gleichheitszeichen sind der aktuelle Branch (oben) und der einzubindende Branch (unten) getrennt. Jeweils am Anfang und Ende des Konfliktbereichs stehen die Namen des betreffenden Branches.
Es bleibt den Entwickler:innen überlassen, sich für eine, beide oder keine der Änderungen zu entscheiden. In diesem Beispiel sollen beide Inhalte erhalten bleiben. Dazu werden die git-Markierungen aus der Datei entfernt und durch Zeilenumbrüche ersetzt. Der Dateiinhalt ist nun:
# Mein erstes Projekt
Eine Übung zur Versionierung mit git.
Alle Information zu den Autoren finden sich in der Datei [AUTHORS.md].Die Datei ist nun konfliktfrei und kann in die Versionierung aufgenommen werden.
7.2.7.1 Rebase
Normalerweise erfolgt das Auflösen von Merge-Konflikten durch die Verantwortlichen des Hauptzweigs. Das ist aus Sicht des Projektmanagements ungünstig. Besser wäre es, wenn nur konfliktfreie Änderungen übernommen werden müssten. git bietet hierzu das Kommando git rebase an. Das Kommando zieht alle Änderungen des Zielzweigs in den aktuellen Arbeitszweig.
git checkout extras
git rebase mainDadurch wird der gleiche Merge-Konflikt wie beim regulären Merge ausgelöst. Dieser Konflikt kann nun durch die Person gelöst werden, die für den Arbeits-Branch verantwortlich ist.
Anschliessend können beide Branches konfliktfrei zusammengeführt werden.
Praxis
Es hat sich als gute Praxis etabliert, Merge-Konflikte immer mit git rebase und nicht mit git merge zu lösen.
7.2.8 Fetch, Pull und Push
git synchronisiert Repositories nicht automatisch. Damit Änderungen in einem Clone oder Fork im eigenen Repository übernommen werden, müssen die Repositories synchronisiert werden.
Das Kommando git fetch synchronisiert die Versionen der Remotes mit dem lokalem Repository. Falls ein Repository mehrere Remotes registriert hat, können alle Änderungen in allen Remotes mit git fetch --all auf einmal abgeglichen werden.
Nach git fetch enthält das lokale Repository alle Versionen der Remotes. Diese Versionen werden allerdings nicht automatich in die lokalen Versionszweige übernommen. Die so synchornisierten Änderungen existieren als eigene Branches im Repository. Im Gegensatz zum regulären Merge, werden diese “Remote-Branches” mit dem Kommando git pull in die lokalen Versionen übernommen. git pull löst alle Unterschiede für den aktuellen Branch im lokalen und remote Repository auf.
Weil intern ein Merge durchgeführt wird, kann auch git pull zu Merge-Konflikten führen. Diese Konflikte müssen gelöst werden, bevor weitergearbeitet werden kann.
Hinweis
git pull führt automatisch ein git fetch aus, falls keine Änderungen für ein Remote-Repository lokal gefunden wurden.
Praxis
Sind für ein Repository mehrere Remotes konfiguriert, dann sollten die einzelnen Remotes einzeln synchronisiert werden.
Das Kommando git push wird zum Synchronisieren des lokalen Repositories mit den Remotes genutzt. Beim git push wird im Remote ein Merge durchgeführt. Führt dieser zu Konflikten, meldet git push einen Fehler, jedoch keinen Merge-Konflikt. Bei Fehlern von git push muss zuerst git fetch und anschliessend ein git rebase ausgeführt werden und eventuelle Merge-Konflikte lokal gelöst werden.
git push kann nur für Clones verwendet werden. Forks können normalerweise nicht direkt in das Upstream-Remote synchronisieren. Sollen Änderungen für ein Upstream Repository vorgeschlagen werden, dann muss ein sogenannter Pull-Request ausgelöst werden. In diesem Fall werden die Änderungen durch ein git pull im Upstream-Repository übernommen.
7.3 git-Projektmanagement
Die im folgenden beschrieben Funktionen sind kein Teil von git, sondern finden sich als Erweiterungen in git-Hosting-Plattformen. Diese Funktionen wurden für den Einstieg in die Verwendung von git-Hosting-Plattformen ausgewählt und zeigen nur einen Bruchteil der Managementfunktionen moderner git-Hosting-Plattformen.
7.3.1 Issues
git-Hosting-Plattformen führen neben dem eigentlichen Repository eine Liste mit Issues. Issues bezeichnen traditionell ein Problem, Fragestellung oder Angelegenheit im oder mit dem Projekt. Das können z.B. noch nicht realisierte Projektziele, fehlende Dokumentation oder auch Sicherheitsproblemen durch Programmierfehler sein. Damit Issues nicht verloren und vergessen werden, sollten sie dokumentiert werden. Dazu dient der Issues-Bereich in git-Hosting-Plattformen.
Die Issues eines Projekts sind nummeriert, so dass über diese Nummer auf das jeweilige Issue referenziert werden kann. Ein Issue besteht immer aus einem Titel, welcher die notwendige Änderung kurz beschreibt. Zusätzlich verfügen Issues über eine Beschreibung, in der detailliert beschrieben werden kann, was das Problem ist und welche Anforderungen erfüllt sein müssen, damit ein Issue erfüllt ist.
Die Issues von git-Hosting-Plattformen haben zwei Zustände: Offen (engl. open) und geschlossen (engl. closed). Offene Issues sind noch nicht bearbeitet. Geschlossene Issues sind bearbeitet und erledigt. Issues können deshalb als To-Do-Liste für ein Projekt verwendet werden: Jedes Issue lässt sich mit Änderungen im Repository verbinden. Weil jede Änderung mit einer Version gleichzusetzen ist, kann ein Issue geschlossen werden, wenn im Repository ein Commit existiert, das die notwendige Änderung enthält.
git-Hosting-Plattformen unterstützen sog. Action-Keywords in Commit-Meldungen. Wird ein solches Keyword zusammen mit der Issue-Nummer verwendet, dann schliesst die Hosting-Plattform das genannte Issue automatisch. Gleichzeitig wird dokumentiert, mit welchem Commit das Issue geschlossen wurde.
Die Möglichkeit ein Issue zu kommentieren ist weitere sehr praktische Funktion. So können Notizen, Gedanken und Recherchen einem Issue zugeordnet werden. Diese Dokumentation wird automatisch mit einem Datum und dem Account-Namen versehen, so dass sich die Arbeit an einem Issue leicht reproduzieren lässt. Der Vorteil dieser Funktion ist, dass so Konzepte und Ideen einem Issue zugeordnet werden können, selbst wenn sich diese nicht im eigentlichen Repository wiederfinden. So kann die Entscheidungsfindung in einem Projekt nachvollziehbar dokumentiert werden.
7.3.2 Pull-Requests
Wenn Code in zwei Code-Zweigen zusammengeführt werden soll, werden sog. Pull-Requests bzw. Merge-Requests erstellt. Ein Pull-Request ist eine Anfrage zum Zusammenführen eines Branches oder eines Forks mit einem anderen Branch.
Hinweis
Ursprünglich wurden Pull-Requests in Form von E-Mails an die Projektkoordination geschickt und enthieleten einen Verweis auf den einzubindenen Fork. In git-Hosting-Plattformen sind Pull-Requests spezielle Issues, die einen Branch oder einen Fork mit dem Repository verknüpfen.
Praxis
Sobald ein Commit in einem Branch vorliegt, kann ein Pull-Request erstellt werden. Es ist eine gute Vorgehensweise, möglichst früh einen Pull-Request zu öffnen.
Wie Issues können Pull-Requests kommentiert werden, so dass notwendige Anpassungen angeregt werden können. Es kann auch die Qualität der Versionen in einem Branch überprüft werden. Entspricht ein Pull-Request nicht den Qualitätsanforderungen eines Projekts, können vor einem Merge die notwendigen Änderungen vorgenommen werden. Alle git-Hosting-Plattformen bieten die Möglichkeit für jeden Pull-Request Projektstandards automatisch zu überprüfen und verhindern das Zusammenführen bei Problemen.
Pull-Requests habe wie Issues den Zustand offen und geschlossen. Sobald ein Merge mit dem Ziel-Branch erfolgt durchfegührt wurde, schliesst die git-Hosting-Plattform den Pull-Request automatisch. Pull-Requests können auch Issues zugeordent werden, so dass ein oder mehrere zugeordnete Issues automatisch geschlossen werden, sobald ein Pull-Request gemerged wurde.
7.4 Anwendungen und Praxistipps
7.4.1 GitHub-Flow
Es hat sich bewährt, jede Aktvität am Repository in einem eigenen Branch durchzuführen. Dabei wird jeder Branch immer mit einem Issue verknüpft. Ist die Arbeit abgeschlossen, dann wird ein Pull-request zur Qualitätskontrolle erstellt. Sind die Änderungen in Ordnung, dann kann dieser Pull-Request mit einem Merge abgeschlossen werden. Der main-Branch enthält bei dieser Vorgehensweise immer eine korrekte und funktionierende Version des Projekts. Diese Vorgehensweise wird als GitHub-Flow (GitHub Inc., o. J.) bezeichnet.
Abbildung 7.1 zeigt ein einfaches Beispiel für den Ablauf des GitHub-Flows.
Der GitHub-Flow arbeitet immer nach dem gleichem Grundschema:
- Es wird ein Issue mit den Anforderungen für die Aufgabe erstellt.
- Es wird ein Issue-Branch erstellt.
- Es werden die Änderungen im Issue-Branch festgehalten.
- Es wird ein Pull-Request für den Issue-Branch erstellt.
- Sind alle Anforderungen erfüllt und existieren keine Merge-Konflikte, wird ein Merge des Issue-Branch mit dem
main-Branch durchgeführt. - Der Issue-Branch wird aus dem Repository gelöscht.
Im GitHub-Flow gelten die folgenden Regeln für die Projektarbeit:
- Branches werden ausschliesslich über Pull-Requests mit dem
main-Branch zusammengeführt. - Alle Pull-Requests beziehen sich auf mindestens ein Issue.
- Es erfolgen keine Commits in den
main-Branch. - Es werden ausschliesslich konfliktfreie Merges durchgeführt. Alle Merge-Konflikte müssen im zugehörigen Issue-Branch gelöst werden.
Ein Issue-Branch ist ein normaler git-Branch mit dem Namen oder der Nummer des Issues. Am einfachsten sind Branchnamen die mit issue_ beginnen und mit der jeweiligen Issue-Nummer enden. Z.B. für das erste Issue eines Projekts würde der zugehörige Issue-Branch issue_1 heissen. Der Vorteil dieser Benennung ist, dass ein Branch einem Issue zugeordnet werden kann, selbst wenn noch kein Pull-Request erstellt wurde.
Es wird empfohlen, einen Pull-Request zu öffnen, sobald eine Version in den Branch committed wurde. Dadurch können automatische Qualitätssicherungsschritte die Arbeit unterstützen. Ein Pull-Request muss spätestens nach vollendeter Arbeit an einem Issue erstellt werden.
Pull-Requests sollten mit Action-Keywords konfiguriert werden, so dass mit dem schliessen des Pull-Requests durch einen Merge das zugehörige Issue automatisch geschlossen wird.
Abschliessend wird der Issue-Branch gelöscht. Technisch wird nur die Verzweigung aus dem Repository entfernt, weil die Versionierung beim Merge erhalten bleibt. Dadurch wird sichergestellt, dass an dieser Aufgabe nicht versehentlich weiter gearbeitet wird.
7.4.2 Dateien und Verzeichnisse von der Versionierung ausschliessen
git meldet “nicht verfolgte”-Dateien, um Datenverlusten vorzubeugen. Nicht alle Dateien in einem Projekt müssen oder sollten versioniert werden. Das gilt meist für die folgenden Kategorien.
- Dateien des Betriebssystems
- Konfigurationsdateien
- Hilfsmodule und Komponenten von Dritten
- Temporäre Dateien und Zwischenergebnisse
Damit diese Dateien nicht versehentlich in der Versionierung erfasst werden, sollten sie aus dem Prozess ausgenommen werden. Dateien und Verzeichnisse können von der Versionierung ausgenommen werden, indem sie in der Datei .gitignore erwähnt werden. .gitignore kann gezielt einzelne Namen oder Namesmuster ausklammern. .gitignore ist Teil der versionierten Daten, so dass sauber nachvollziehbar ist, welche Dateien aus der Versionierung ausgenommenen werden sollten.
Eine Datei wird nur ignoriert, wenn sich noch nicht in der Versionierung erfasst wurde.
Achtung
Eine Datei wird von der Versionierung ausgeschlossen, wenn eine der folgenden Regeln zutrifft.
- Der Datei- oder Verzeichnisname ist explizit in
.gitignoregelistet. Für Namen in Unterverzeichnissen muss dazu der Gesamtepfad angegeben sein. - Eine Datei oder ein Verzeichnis liegt in einem Verzeichnis, dass ignoriert wird.
- Der Datei- oder Verzeichnisname wird durch ein Namesmuster erfasst.
Die folgenden Namesmuster sind gebräuchlich:
*/dateiname- eine Datei oder ein Verzeichnis mit einem bestimmten Namen liegt in einem Verzeichnis im Projektverzeichnis.**/dateiname- eine Datei oder ein Verzeichnis liegt an beliebiger Stelle im Repository.*.tmp- alle Dateien oder Verzeichnisse im Projektverzeichnis, die auf.tmpenden.bild*- alle Dateien oder Verzeichnisse im Projektverzeichnis, die mitbildbeginnen.
Gelegentlich kommt es vor, dass festgestellt wird, dass eine oder mehrere Dateien ignoriert werden soll, obwohl sie bereits in die Versionierung aufgenommen wurde. In diesem Fall erscheit es, als ob .gitignore nicht funktioniert. Das liegt daran, dass git eine Datei nur ignoriert, wenn diese nicht in der Versionierung erfasst wurde. Um eine bereits erfasste Datei zu irgnorieren, muss diese Datei aus dem Versionsdatenbank mit git rm entfernt werden.
Beispiel 7.1 (Eine typische .gitignore-Datei für ein R-Projekt.)
# Ignore MacOS Filesystem Metadata
**/.DS_Store
# R-specific Files
.Rhistory
.Rapp.history
.RData
.RDataTmp
.Ruserdata
.Renviron
*-Ex.R
/*.tar.gz
/*.Rcheck/
.Rproj.user/
vignettes/*.html
vignettes/*.pdf
rsconnect/
.httr-oauth
*_cache/
/cache/
*.utf8.md
*.knit.md
po/*~
_bookdown_files/
_book
.quarto/
/.quarto/
MacOS Ordnerinformation
MacOS legt verdeckt Ordnerinformationen in Verzeichnissen an. Diese Dateien enthalten keine projektrelevanten Daten und sollten nicht versioniert werden. Diese Dateien haben immer den Namen .DS_Store und können in jedem Verzeichnis erscheinen. Deshalb sollte die Zeile mit dem Inhalt **/.DS_Store immer Bestandteil der .gitignore-Datei sein.
7.4.3 Repository-Organisation
Die Arbeit mit Git und den anderen Hosting-Plattformen erscheint oft mühsam und aufwändig. Das gilt speziell für grösseres Umorganisieren eines Repositories. Gerade bei komplexen Projekten sollte deshalb möglichst früh die Organisation des Versionsmanagements festgelegt werden.
In der Praxis finden sich drei Organisationsstrategien.
- Monorepo
- Projektrepo
- Microrepo
Die Wahl der Repository-Organisation hängt stark von den Projektanforderungen ab.
7.4.3.1 Monorepo
Bei der Monorepo-Strategie werden alle Dateien in einem einzigen Repository organisiert. Diese Strategie ist besonders bei Projektbeginn oder bei einfachen Projekten mit geringer funktionaler Trennung geeignet. Der Vorteil dieser Strategie ist, dass alle Daten in einem Repository zusammengefasst vorliegen und als Ganzes verwaltet werden können.
Für komplexe Projekte wird diese Organisationsstrategie normalerweise mit dem Git-Flow als Branching-Strategie kombiniert. Dabei müssen alle Projektteile aufeinander abgestimmt werden und benötigen eine konsitente Qualitätskontrolle, weil alle Änderungen voneinander abhängig sind. Komplexe Änderungen beeinflussen wegen der linearen Abhängigkeit der Versionen deshalb alle anderen Bereich und sind deshalb wesentlich schwerer zu korrigieren.
7.4.3.2 Projektrepo
Die Projektrepo-Strategie ist eine Variante der Monorepo-Strategie für komplexe Projekte, mit klar getrennten aber voneinander abhängigen Projektteilen. Dazu werden einzelene Projektteile in eigene Repositories ausgegliedert und als git-Submodule in das Haupt-Repository eingebunden. Solche Submodule können unabhängig vom Hauptprojekt entwickelt werden und auch in anderen Projekten wiederverwendet werden. Die Integration eines Submoduls erfolgt für einen bestimmten Commit oder ein bestimmtes Tag. Dadurch wird eine differenziertere Qualitätskontrolle möglich.
7.4.3.3 Microrepo
Bei der Microrepo-Strategie werden alle Projektteile in eigenen Repositories unabhängig voneinander geführt, so dass nur der jeweilige Projektteil und die zugehörige Konfiguration in einem Repository vorliegen.
Bei der Microrepo-Strategie werden Daten, Code und Konfiguration grundsätzlich immer voneinander getrennt und werden in eigenen Repositories verwaltet. Damit ist diese Strategie die Antithese zum Monorepo. Die Integration der Komponenten erfolgt über das lokale Dateisystem oder über Packetmanager und git-Tags.
Diese Strategie eignet sich für Datenprojekte, Projekte mit wenigen direkten Abhähngigkeiten oder Projekte mit verschiedenen Anwendungsgebieten (engl. Deployments). Durch klar getrennte Repositories lassen sich die einzelnen Komponenten in unterschiedlichen Kontexten problemlos unabhängig voneinander publizieren und anpassen. Deshalb ist diese Strategie besonders für Projekte mit sensitiven Daten, wie z.B. Patientendaten, oder Konfigurationen, wie beispielsweise Passwörtern, geeignet, bei denen die Datenverarbeitung keine sensitiven Teile hat.
7.5 git and Visual Studio Code
7.5.1 Anmeldung
GitHub existieren zwei Varianten der Hosting-Plattform. Die öffentliche git-Hosting Plattform ist GitHub.com. Daneben gibt es GitHub Enterprise Server. Dabei handelt es sich um eine nicht öffentliche git-Hosting-Plattformen auf der gleichen Software-Grundlage wie GitHub.com. Diese Variante wird häufig von Unternehmen verwendet, die zwar git und GitHub verwenden wollen, aber keine öffentliche Präsenz für ihre Daten- und Code-Projekte wünschen oder haben dürfen. Beide Varianten werden von Visual Studio Code für das Versionsmanagement direkt unterstützt. Damit das reibungsfrei funktioniert, muss man Visual Studio Code mit dem eigenen Account an beiden Plattformen anmelden.
Am elegantesten geht die Anmeldung an GitHub und GitHub Enterprise Servern mithilfe der Erweiterung GitHub Pull Requests. Diese Erweiterung muss installiert werden, um den vollen GitHub-Funktionsumfang zu nutzen.
Sobald diese Erweiterung installiert ist, kann man sich mit einem GitHub Enterprise Server verbinden.
Dazu muss der GitHub Enterprise Server zuerst in den Einstellungen konfiguriert werden: Unter der Einstellug GitHub-Enterprise: Uri muss die Server URL eingetragen werden.
Anschliessend erscheint im Menu Accounts die Möglichkeit, sich mit diesem Server zu verbinden.
Beim Verbinden wird ein Code angezeigt, der für die Verbindung benötigt wird. Im entsprechenden Dialog muss Copy & Continue to GitHub ausgewählt werden. Dieser Dialog leitet auf die Seite des GitHub Enterprise Servers um.
Auf dem GitHub Server muss Visual Studio Code der Zugriff freigegeben werden. Ist das Erfolgt erscheinen alle angemeldeten Server im Accounts-Menu.
7.5.2 Arbeitsbereiche
Visual Studio Code arbeitet mit sog. Arbeitsbereichen oder Workspaces. Wird mit mehreren Repositories gearbeitet, dann werden die Repositories einzeln dem Arbeitsbereich zugewiesen.
Achtung ☠️☠️
Auch wenn es auf den ersten Blick einfacher aussieht, sollte nie das übergeordnete Verzeichnis, in welchem die gewünschten Repositories, direkt in Visual Studio Code geöffnet werden. Dadurch wird die Arbeit mit Daten in den Repositories und die Zusammenarbeit stark erschwert!
Um mehrere Repositories in Visual Studio Code zu öffnen, wird zuerst Visual Studio Code ohne eine Datei oder Respotory geöffnet. Visual Studio Code erstellt so einen neuen Arbeitsbereich.
Anschliessend wird das erste Repository mit Ordner öffnen in den Arbeitsbereich geladen. Dieses Repository wird dann zu oberst im Arbeitsbereich stehen. Die Reihenfolge der Repositories lässt sich später durch Ziehen mit der Maus auch noch anpassen.
Anschliessend werden alle weiteren Repositories einzeln über das Kontextmenu Ordner zum Arbeitsbereich hinzufügen eingebunden werden. Dieser Menupunkt führt zu einem Auswahldialog, in welchem die Ordner der Repositories ausgewählt werden können.

Ordner zum Arbeitsbereich hinzufügen
Praxis
Weil das Einbinden mehrerer Repositories in Visual Studio Code recht umständlich ist, bietet es sich an, die Arbeitsbereiche abzuspeichern. So kann die Arbeitsumgebung für mehrere Projekte getrennt gehalten und der gespeicherte Stand direkt geöffnet werden. Dazu muss ein Arbeitsbereich in einer Datei gespeichert werden. Visual Studio Code bietet das Speichern eines Arbeitsbereichs jeweils beim Schliessen des jeweiligen Arbeitsbereichsfensters an.
Es ist hilfreich solche Arbeitsbereiche in ein separaten Repository abzulegen und ebenfalls zu versionieren. Über ein solches Projekt lassen sich die Visual Studio Code-Einstellungen über mehrere Rechner leicht teilen.
7.5.3 Ausführungskontext
Der Ausführungskontext bezeichnet die Umgebung in denen Programme gestartet werden. Dazu gehört das Start-Verzeichnis, Systemparameter und vieles mehr. Programme nutzen automatisch diesen Ausführungskontext, um Dateien auf dem jeweiligen System zu finden.
Beim Ausführen von Code verwendet Visual Studio Code als Ausführungskontext jeweils den am weitesten übergeordneten Ordner eines Programms im Arbeitsbereich. Idealerweise ist dieser Ordner das Repository-Verzeichnis. Das ist deshalb praktisch, weil innerhalb eines Repositories die Organisation und Position aller Dateien bekannt ist. Diese Voraussetzung gilt nicht für die dem Repository übergeordneten Verzeichnisse, die beliebige Namen haben können. Dadurch kann beim datenorientierten Programmieren keine sichere Annahme über die Dateistruktur gemacht werden und der Code muss für jeden Rechner angepasst werden, auf welchem der Code laufen soll. Diese zusätzliche Arbeit gilt es zu vermeiden.
Macht der Code in einem Repository keine zusätzlichen Vorgaben an den Ausführungskontext jenseits des Repositories, dann wird das Repository als selbst-bezogen oder self-contained bezeichnet. Damit Visual Studio Code solchen selbst-bezogenen Code korrekt ausführen kann, muss das gewünschte Repository als Ordner dem aktuellen Arbeitsbereich hinzugefügt werden.
7.6 Repositories im Dateisystem
git-Repositories umfassen nicht nur den aktuellen Stand der Arbeit, sondern immer die vollständige Versionsverlauf eines Projekts. Dadurch ist es möglich auch ohne Datenverbindung an Projekten zu arbeiten. Aus diesem Grund verbrauchen diese Repositories schnell recht viel Speicherplatz. Entsprechend sollten git-Repositories nicht gleichzeitig mit Cloud-Speichern wie OneDrive, iCloud oder Google Drive synchronisiert werden.
Unabhängig von der Repository-Organisation arbeitet man regelmässig mit mehreren Repositories. Damit diese nicht versehentlich in einem Cloud-Speicher landen, hat sich die folgende Strategie bewährt:
Es sollte ein eigener Ordner für Repositories direkt im Heimatverzeichnis erstellt werden (Siehe Kasten). Geeignete Namen für dieses übergeordnete Verzeichnis sind z.B. Repositories, Code oder Src. In diese Verzeichnis werden die eigentlichlichen git-Repositories gecloned. Gegebenenfalls ist es sinnvoll zusätzliche Unterverzeichnisse für Repository-Gruppen zu erstellen.
Wurde im Heimatverzeichnis ein entsprechend bezeichnetes Verzeichnis angelegt, so wird dieses von den Cloud-Speicher-Systemen ignoriert.
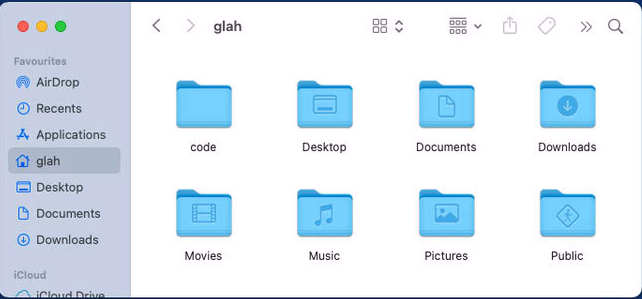
code-Verzeichnis unter MacOS
Repositories-Verzeichnis unter Windows
Achtung
Repositories sollten nie auf dem Desktop oder im Verzeichnis Dokumente oder im Synchronisationsordner der bevorzugten Cloud-Speicher abgelegt werden, weil diese mit der Cloud synchronisiert werden.
Das Heimatverzeichnis
Alle modernen Betriebssysteme sind sogenannte Mehrnutzersysteme. D.h. es können mehrere Nutzer das gleiche System verwenden, wobei jede Person einen eigenen Arbeitsbereich zur Ablage von Dateien hat. Das Verzeichnis, in welchem dieser Arbeitsbereich gespeichert wird, heisst Heimatverzeichnis oder Home-Verzeichnis.
In der Standardeinstellung von Windows und MacOS ist es jedoch nicht intuitiv, das eigene Heimatverzeichnis zu finden.
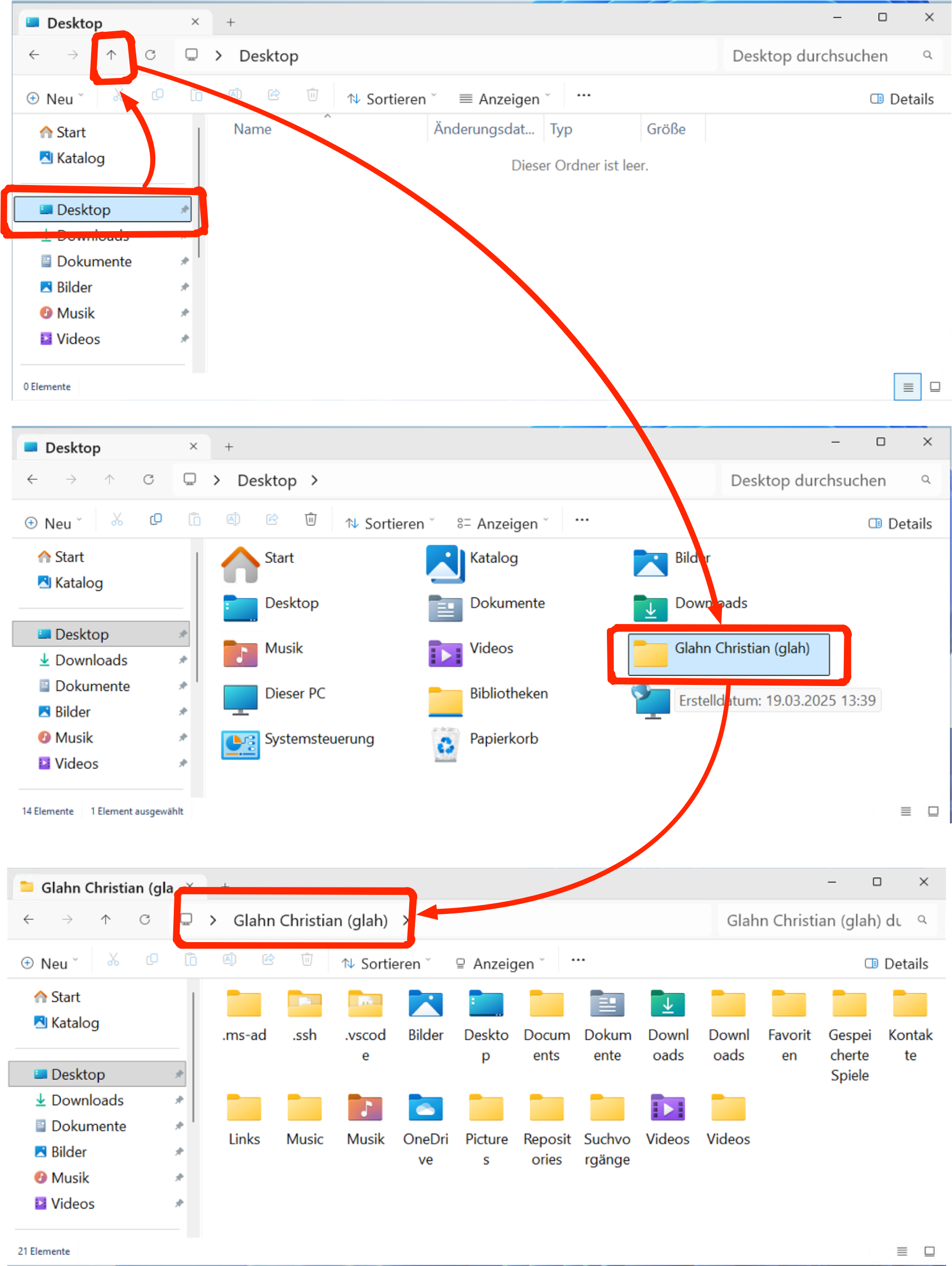
Unter Windows wählt man dazu im Explorer den Schnellzugriff für das Desktop aus, tippt anschliessen auf den Pfeil nach oben. Im der folgenden Ansicht taucht ein Verzeichnis mit den Namen des aktuellen Anwender*In auf. Auf dieses Verzeichnis muss doppeltgeklickt werden, um das Heimatverzeichnis zu erreichen.
Unter MacOS wählt man im Finder in den Favoriten den Schreibtisch aus. Anschliessend tippt man auf der Tastatur die Kombination Command + 🔼, um in das Heimatverzeichnis zu gelangen.
Das Heimatverzeichnis sollte für den einfachen Zugriff im Schnellzugriffsbereich abgelegt werden. Dazu wird sowohl unter MacOS als auch unter Windows der Ordner mit der Maus in den jeweiligen Schnellzugriffsbereich gezogen.